经常捣鼓大模型的朋友都知道,各大厂商提供的模型是生产力工具。可以蹭,但也需要计算性价比。一些小的任务或是隐私任务,放在本地更合适。随着越来越多开源的 SLM(Small Language Model)智力水平的提升,部署到本地也是一个选择。
作为一个玩过智能家居、玩过路由器、玩过 NAS 的人,本地模型当然也要拉下来玩玩。这不仅可以用来窥探模型本身的技术架构,还可以解决手边的小问题。但技术选型过程中,会遇到两个问题:一个是本地显/内存有限的前提下,最有性价比或者说最有智力的模型是谁?第二个问题是,我该用什么框架来部署服务。
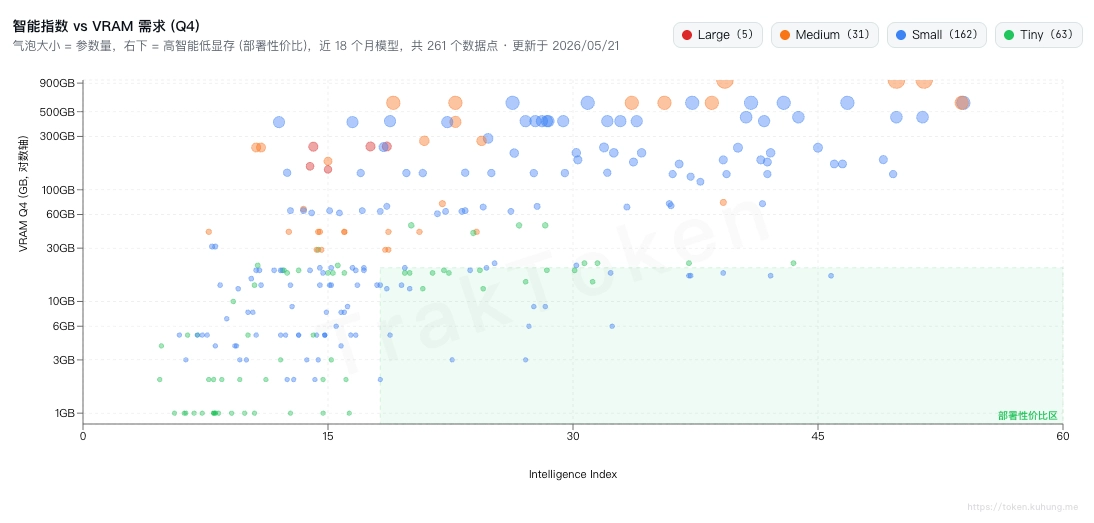
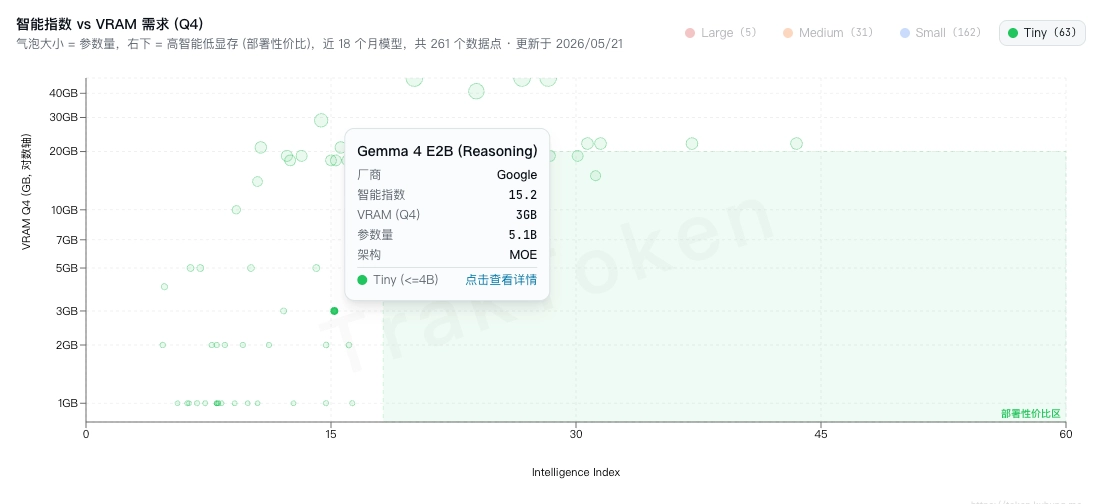
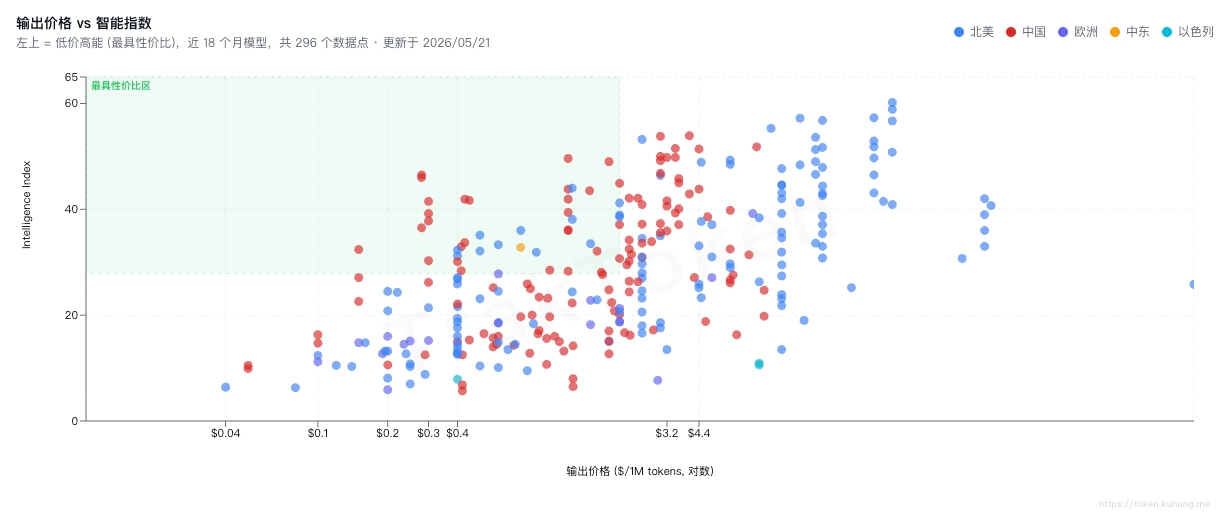
在不知道咋选的时候,我选择用最新的开源模型。但是不少模型其实是有显存要求的。最新是好,但不一定能部署到本机。后来,我通过拉取最新的模型数据,构造并发布了一个网页应用 Traktoken,这下可以直观了解模型能力与所需显存间的关系。
模型框架方面,我选择用适合本机显存的最强开源模型结合早期占据市场心智的 Ollama。但这真的是最优解吗,我有时候也会问自己。这个疑惑,在我开发 PageGrok(一款浏览器插件 AI 产品)时,到达巅峰。
为什么要做这个评测?
首先是实际的业务痛点。PageGrok 是一款浏览器插件,用来在不跳转、不用外部 API(省事省钱)的情况下,解读当前页面的内容。其不用外部 API,靠的就是用户自己部署的本地模型。本意是减少用户动作,但真上线后发现:用户选中内容并发送给本地模型处理时,响应延迟非常大。
虽然本地不花 API 费用,但是时间也是钱啊(摔)。动辄数十秒的冷启动时间,让用户一度以为插件失灵。显然,瓶颈不在插件和通信,是本地服务的问题。框架性能表现成为必须关注的核心。到底咋回事,为啥 Chatbot 感觉不明显的模型加载和提示词填充,在这个场景下延迟明显?
其次是新老框架的交替和抉择。我从去年就开始在生产活动中使用本地模型(例如在“相亲小镇”项目中),一直使用 Ollama 框架,部署 Gemma 3 模型作为底座模型。早期在 MacBook 上风扇转得飞快,但迁移到 Linux 服务器后,GPU 你转就转吧。
早在 23 年,苹果就推出了专为 Apple Silicon 优化的 MLX 框架。但直到 26 年上半年,在其基础上开发的 oMLX 才受到大范围关注,社媒上看到其声称更好适配苹果设备。没过多久,Ollama 也在新版本声称支持了 MLX 框架。这种感觉就像是:“你别迁移,我能行”。
真的行吗?我一开始下载的是 LM Studio,它出现的时间比 Ollama 更早。Ollama 后来居上,凭借其 YC 投资背景和简洁的设计,很快占据了不少市场。面对不同的框架,我的核心疑问随之而来:最适合 Mac 电脑部署的本地框架到底是什么? 拒绝感觉良好,得有套系统的测评手段。
评测指标体系设计
在开始自己重复造轮子前,我也系统看了现有的解决方案。大家主要关注三个方面的指标,分别是用户体验指标(如:TTFT 首字延迟时间)、成本指标(如:TPS token 吞吐量)、资源消耗(如:GPU 占用情况)。
这个方向的测评,我们不关注模型在测评集上的表现。即默认相同模型权重在 MMLU 这类测评的表现是一致的(实际上不一致,会因为数据处理方式的差异,有略微表现差异)。
关于这部分的讨论,其实早在 23、24 年就有了。不少模型平台提供方也提供了它们自己的脚手架工具,例如 huggingface/inference-benchmarker。模型部署框架方也做了不少工作,例如 oMLX 就自带测评工具。
不过,总的看来,这些测评工具都多少有些耦合和过度设计。比如 oMLX 这套只能说明它自己的模型效果,无法横向测评其他框架结果。Hugging Face 这套则是和它自身的生态绑定,学习曲线比较陡峭。
网上也有不少开源项目,目前看来都缺少维护,简单 vibe 发布后,后续就没有迭代了。基于上述情况,我决定自己根据这些测评角度,开发一套简单易用、跨多个框架的测评工具。
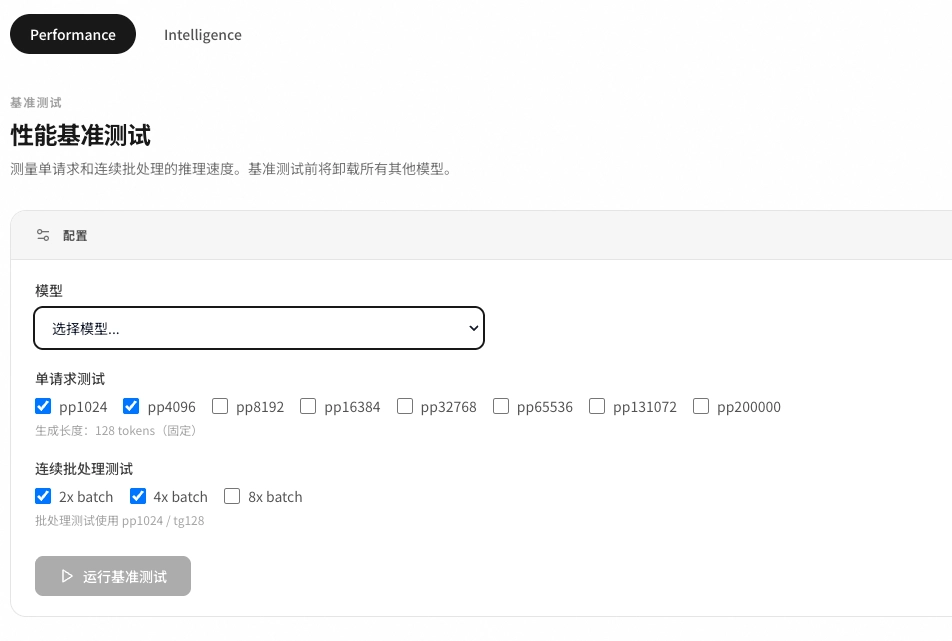
在上述背景下,LLM Bench 应运而生。这是一个网页应用,用户可以直接连接本地大模型,简单点击即可进行测评。
核心指标
-
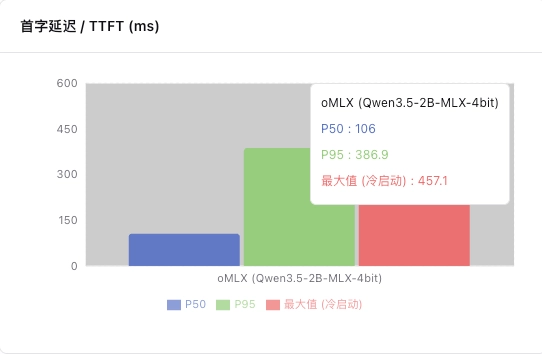
首字延迟(TTFT):直接决定用户等待焦虑度,是本地体验的关键。一般来说,线上服务的等待时间控制在 2-3s 内会比较好。TTFT 实际上是排队等待 + 提示词预填充时间(Prefill Time)+ 网络波动的总和。从用户角度来说,就是我发消息过去,直到屏幕上开始出现字的等待时间。
-
输出速度(Tokens Per Second):首个 token 到最后一个 token 之间的 decode 速率。分母不包含 TTFT,确保 prefill 和 decode 正交衡量。人类的阅读速度一般是每秒 4 个字符,感觉流畅要大于 30 个 token/s。相同硬件条件下,TPS 越高,反映出资源利用率越高,成本控制越好。
除开上述两个指标外,本地模型还有个指标非常重要,是冷启动时的 TTFT。这反映模型加载到框架到出现字符的时间,这也是前文我们体感觉得慢的地方。这个指标,在其他测评框架中基本整合进 TTFT,但我觉得很有必要单独拎出来。
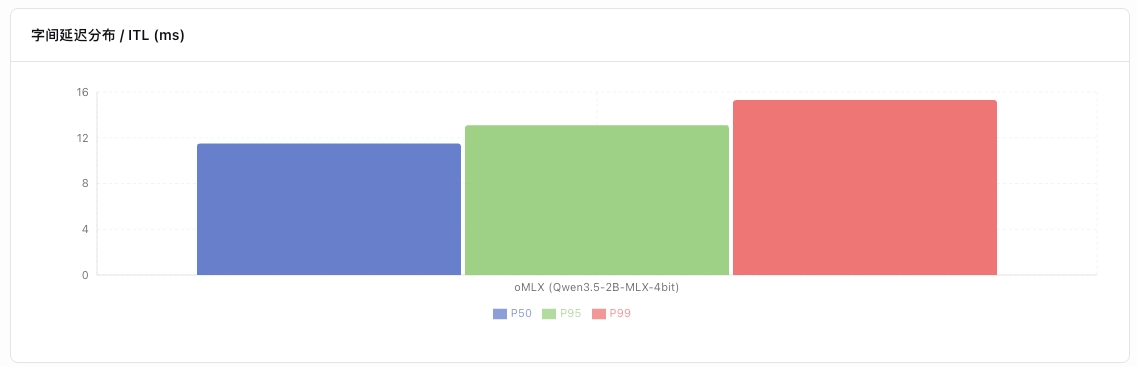
另外,还会有**字间延迟分布(Inter-Token Latency)**这个指标,用来衡量两个 token 之间的时间间隔,越高表示卡顿越明显,用户感知为“一卡一卡的”。内存管理或者是显存带宽出现问题,都会导致这个指标升高。
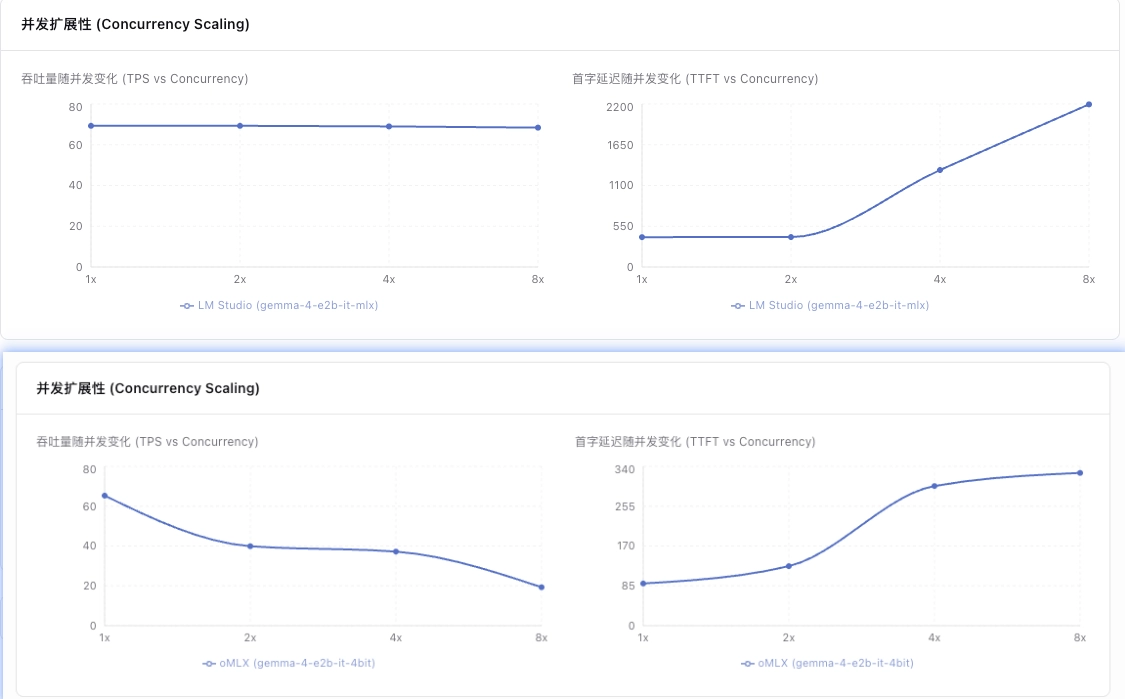
**并发扩展性(Scalability)**则是指当并发请求出现时,模型的表现情况。计算方式为 TPS@concurrency=8 / TPS@concurrency=1。比值 1.0 表示完美扩展(并发不影响单请求速度),0.15 以下表示严重退化。
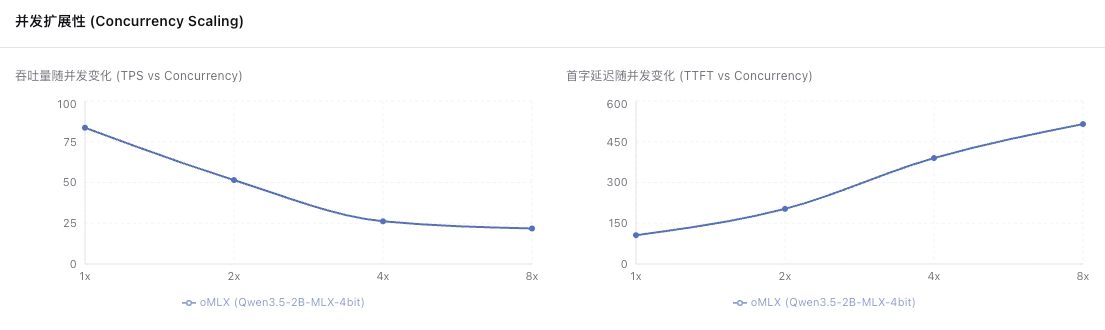
各框架与模型表现对比
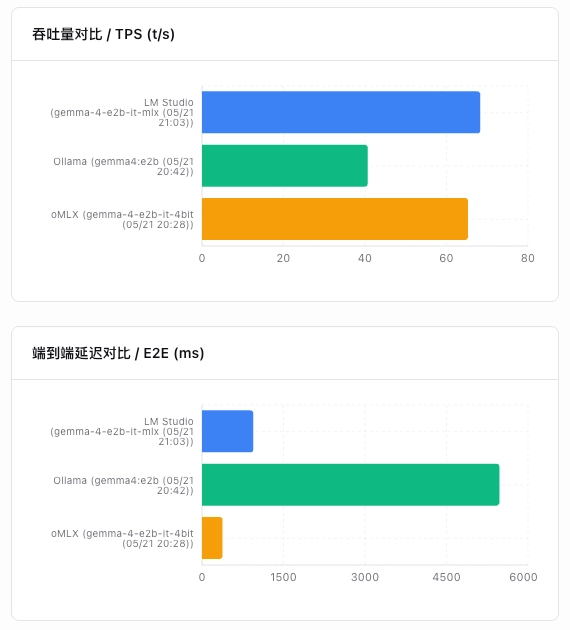
说完测评指标,我们来看不同框架下,相同模型的表现情况。本次测试了三个框架,分别是 Ollama、LM Studio 以及 oMLX。我的 MBP 是 16G 内存,根据 Traktoken 的开源模型智能指数与 VRAM 需求图,本次参加对比的模型是 Gemma 4 E2B。其中需要注意的是,Ollama 是默认 GGUF 格式,LM Studio 和 oMLX 选择的是 MLX 格式的模型权重。
框架表现结论:整体来说,LM Studio 的总和评分最高;oMLX 受制于并发能力,得分垫底。但若不考虑并发,单点情况下 oMLX 的冷启动和首字加载优于 LM Studio,吞吐量优于 Ollama。
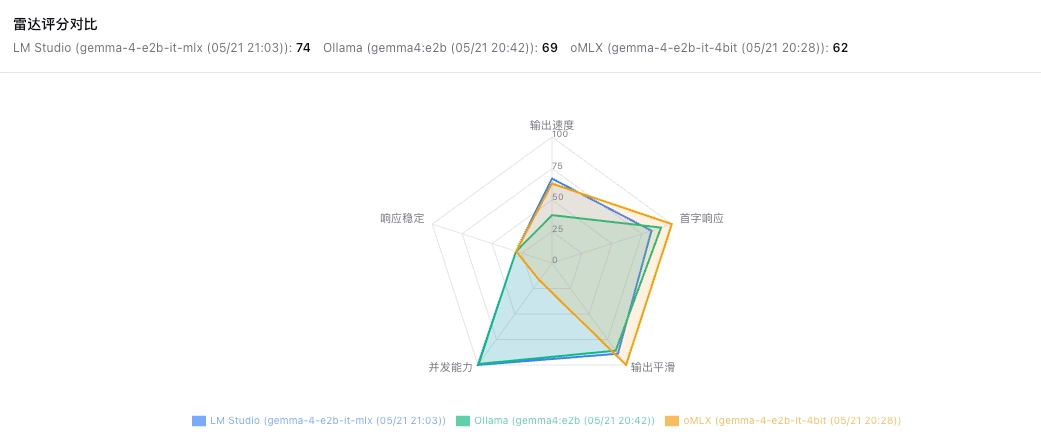
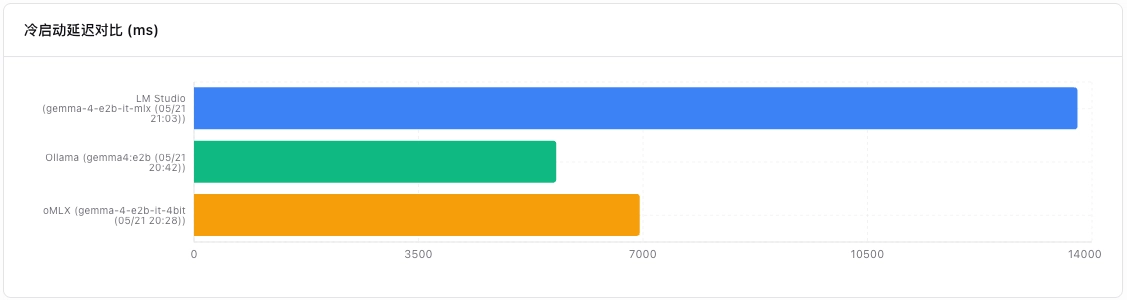
结论与使用者建议
从上面的图表,我们可以轻易对比得出理想的框架。就我来说,目前可选项是 oMLX,如果有高并发需求且不看重冷启动延迟,那么 LM Studio 是相对较好的选择。而 Ollama,虽然它声称新版本已经支持了 MLX 格式的权重文件,但下载的时候提供的仍然是 llama.cpp 支持的 GGUF,需要额外的转换。
当然,我们的测试也不是没有局限。我们并没有做额外的操作,来检查并控制它们的系统配置参数一致,仅使用框架默认的参数。所以,就单个框架本身,肯定是有优化空间的。这点,读者朋友们可以自己试试。
目前,我们的测评工具开源在 GitHub - benchmark-for-LLM,欢迎关注 star 和一起改进。对于无法跨域暴露给外网地址的,还提供了自部署和 Python 包两种选择。Python 包地址:llm-benchmark-runner。
如果你对我的浏览器本地 AI 插件感兴趣,Chrome 商店搜索 PageGrok 即可获得,或者直接访问 PageGrok 官网 下载安装插件。目前我日常深度使用中,未来还会有更多的体验优化,欢迎关注。
如果你对 Traktoken 感兴趣,可访问 Traktoken,了解我每日追踪的 500 多个大模型关于能力、定价的数据信息,以及关于本地部署大模型参数量的估算数据。
最后,拒绝感觉有效,让实验数据说话。
参考资料
- A collection of benchmarks for LLM inference engines: SGLang vs vLLM - Reddit r/LocalLLaMA 社区讨论帖
- AI API 性能测试器 - 在线工具网页
- JohnMing143/llm-api-speedtester - 开源测速工具代码库
- coder543/llm-speed-benchmark - 开源测速工具代码库
- hyscale-lab/LLM-Benchmarking - 全景基准测试框架代码库
- luminal-ai/simple_benchmarking - 简易推理服务测试脚本库
- huggingface/inference-benchmarker - Hugging Face 官方推理基准测试工具
- LLM Inference Benchmarking - Measure What Matters - DigitalOcean 技术博客
- LLM Inference Benchmarking: Fundamental Concepts - NVIDIA 技术博客
- BENCH360 - Benchmarking Local LLM Inference from 360° - 学术研究论文